
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 네이버 이미지 크롤링 on Google, you do not find the information you need! Here are the best content compiled and compiled by the toplist.tfvp.org team, along with other related topics such as: 네이버 이미지 크롤링 네이버 이미지 크롤링 막힘, 네이버 이미지 크롤링 selenium, 네이버 이미지 크롤링 API, 구글 이미지 크롤링, 네이버 블로그 이미지 크롤링, Python 이미지 크롤링, 네이버 이미지 검색 API, 파이썬 이미지 크롤링 예제
Table of Contents
[Python] Selenium을 사용한 네이버 이미지 크롤링 — 오늘의 기록
- Article author: gksdudrb922.tistory.com
- Reviews from users: 25256
 Ratings
Ratings - Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about [Python] Selenium을 사용한 네이버 이미지 크롤링 — 오늘의 기록 [Python] Selenium을 사용한 네이버 이미지 크롤링. danuri 2021. 9. 8. 00:46. 진행 중인 프로젝트에서 음식 이미지를 사용할 일이 있어서 이미지 크롤링에 대해 찾아 … …
- Most searched keywords: Whether you are looking for [Python] Selenium을 사용한 네이버 이미지 크롤링 — 오늘의 기록 [Python] Selenium을 사용한 네이버 이미지 크롤링. danuri 2021. 9. 8. 00:46. 진행 중인 프로젝트에서 음식 이미지를 사용할 일이 있어서 이미지 크롤링에 대해 찾아 … 진행 중인 프로젝트에서 음식 이미지를 사용할 일이 있어서 이미지 크롤링에 대해 찾아보기 시작했다. 여러 사이트를 뒤져봤는데, 그 중 네이버 이미지에는 CCL 상업적 이용 가능 옵션이 있어서 보다 안전하게 프..
- Table of Contents:
블로그 메뉴
인기 글
태그
최근 댓글
최근 글
티스토리툴바
![[Python] Selenium을 사용한 네이버 이미지 크롤링 — 오늘의 기록](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdULn9W%2FbtrehFv6bx9%2FeamBlk2FZYpkBguaLirwmk%2Fimg.png)
Naver 이미지 크롤러
- Article author: velog.io
- Reviews from users: 16005 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about Naver 이미지 크롤러 이미지 크롤러 – Naver. Naver Open API를 이용한 이미지 url 가져오기. 공식적인 방법으로 어플리케이션을 등록을 통해 API를 사용할 수 있다. …
- Most searched keywords: Whether you are looking for Naver 이미지 크롤러 이미지 크롤러 – Naver. Naver Open API를 이용한 이미지 url 가져오기. 공식적인 방법으로 어플리케이션을 등록을 통해 API를 사용할 수 있다. 공식적인 방법으로 어플리케이션을 등록을 통해 API를 사용할 수 있다.웹드라이버를 이용한 방법에 비해 옛날 이미지가 많이 포함되어 있다.매우 빠른 검색 속도하루 25,000 쿼리 제한쿼리당 최대 1000개의 이미지 획득가능Selenium 은 브라우저의 웹드라이버를 이용
- Table of Contents:

네이버 이미지 웹크롤링
- Article author: sulung-sulung.tistory.com
- Reviews from users: 18952 Ratings
- Top rated: 3.3
- Lowest rated: 1
- Summary of article content: Articles about 네이버 이미지 웹크롤링 import urllib.request from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.keys import Keys import … …
- Most searched keywords: Whether you are looking for 네이버 이미지 웹크롤링 import urllib.request from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.keys import Keys import … import urllib.request from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.keys import Keys import time binary = ‘chromedriver.exe’ options = webdriver.ChromeO..
- Table of Contents:
태그
관련글
댓글1
공지사항
최근글
인기글
최근댓글
태그
전체 방문자
네이버 웹 이미지 크롤링(Crawling)하기.
- Article author: namhandong.tistory.com
- Reviews from users: 42412 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about 네이버 웹 이미지 크롤링(Crawling)하기. 네이버에서 이미지들을 크롤링하여 이미지 파일을 저장하고, zip 파일로 압축하는 과정입니다. 머신러닝을 학습하기 위해서는 상당한 양의 데이터가 … …
- Most searched keywords: Whether you are looking for 네이버 웹 이미지 크롤링(Crawling)하기. 네이버에서 이미지들을 크롤링하여 이미지 파일을 저장하고, zip 파일로 압축하는 과정입니다. 머신러닝을 학습하기 위해서는 상당한 양의 데이터가 … https://github.com/jun7867/Web_Image_Crawling jun7867/Web_Image_Crawling Naver, Google Website Image Crawling . Contribute to jun7867/Web_Image_Crawling development by creating an account on GitHub…
- Table of Contents:
‘데이터 처리데이터 처리’ Related Articles
티스토리툴바

브라보 마이라이프 :: 파이썬으로 네이버 이미지 크롤링하기 (Image Crawling)
- Article author: ultrakid.tistory.com
- Reviews from users: 42980 Ratings
- Top rated: 3.2
- Lowest rated: 1
- Summary of article content: Articles about 브라보 마이라이프 :: 파이썬으로 네이버 이미지 크롤링하기 (Image Crawling) 몇가지 라이브러리와 파이썬을 이용하여 크롤링하는 예제를 돌려보겠습니다. 크롤링(Crawling)이란? 웹 상에 존재하는 갖가지 컨텐츠를 수집하는 작업 … …
- Most searched keywords: Whether you are looking for 브라보 마이라이프 :: 파이썬으로 네이버 이미지 크롤링하기 (Image Crawling) 몇가지 라이브러리와 파이썬을 이용하여 크롤링하는 예제를 돌려보겠습니다. 크롤링(Crawling)이란? 웹 상에 존재하는 갖가지 컨텐츠를 수집하는 작업 … 몇가지 라이브러리와 파이썬을 이용하여 크롤링하는 예제를 돌려보겠습니다. 크롤링(Crawling)이란? 웹 상에 존재하는 갖가지 컨텐츠를 수집하는 작업으로, 다양한 프로그램을 만들 수 있습니다. 예를 들어, 인터..
- Table of Contents:
파이썬으로 네이버 이미지 크롤링하기 (Image Crawling)
티스토리툴바
Object Detection을 위한 네이버 이미지 크롤링 구현
- Article author: candletheif.tistory.com
- Reviews from users: 33798 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about Object Detection을 위한 네이버 이미지 크롤링 구현 Selenium을 이용한 네이버 이미지 크롤링. 네이버에서는 빠른 검색을 위해 한 번에 50장의 사진을 불러오고 스크롤을 다 내리면 다시 50장을 불러오는 … …
- Most searched keywords: Whether you are looking for Object Detection을 위한 네이버 이미지 크롤링 구현 Selenium을 이용한 네이버 이미지 크롤링. 네이버에서는 빠른 검색을 위해 한 번에 50장의 사진을 불러오고 스크롤을 다 내리면 다시 50장을 불러오는 … 이미지 크롤링 이미지 크롤링은 Object Detection을 위한 학습에 필요한 과정입니다. 특정 객체를 학습 시키기 위해선 많은 이미지들이 필요하고 이를 일일이 다운 받기엔 너무 많은 시간이 듭니다. 이를 자동화..
- Table of Contents:
이미지 크롤링
Selenium을 이용한 네이버 이미지 크롤링
관련글
댓글2
공지사항
최근글
인기글
최근댓글
태그
전체 방문자
Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결)
- Article author: j-ungry.tistory.com
- Reviews from users: 21916 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결) Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결) · 1. 검색부분 구현 및 … …
- Most searched keywords: Whether you are looking for Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결) Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결) · 1. 검색부분 구현 및 … 참고는 프로그래머 김플 스튜디오 유튜브 오늘은 네이버에다 검색어를 검색하면 이미지 검색결과를 자동으로 다운받는걸 만들어볼거다 ! 과정 (내 생각임) 1. 검색부분 구현 및 html 불러오기 2. html 분석을 통해..
- Table of Contents:
정구리의 우주정복
Python 웹크롤링 (Web Crawling) 02 네이버 이미지 검색결과 다운로드 프로그램 ([SSL CERTIFICATE_VERIFY_FAILED] 오류해결) 본문
![Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결)](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FF3CRg%2FbtqC3NJwOph%2Fe3gFiT6cVVlbWdV4kI9hV1%2Fimg.png)
See more articles in the same category here: Top 165 tips update new.
[Python] Selenium을 사용한 네이버 이미지 크롤링
진행 중인 프로젝트에서 음식 이미지를 사용할 일이 있어서 이미지 크롤링에 대해 찾아보기 시작했다.
여러 사이트를 뒤져봤는데, 그 중 네이버 이미지에는 CCL 상업적 이용 가능 옵션이 있어서 보다 안전하게 프로젝트에 사용할 수 있지 않을까 싶어서 네이버에서 크롤링을 하기로 했다.
구글링을 열심히 해서 여러 크롤링 코드들을 참고했지만, 실제로 잘 동작하지 않아서…. 직접 참고한 몇몇 코드를 따와서 재구성해보았다.
일단 beatifulsoup으로 크롤링을 시도했을 때는 특정 태그부터는 parser가 접근을 하지 못해서 (해당 태그에 dataGroupKey 같은 인증 관련된 부분이 있었는데 이 문제인듯 싶다…) selenium을 통해 구현하기로 했다.
selenium 설치
우선 selenium 사용을 위해 터미널에 다음 명령어를 입력해준다.
pip install selenium
chrome driver 설치
다음은 google Chrome Driver를 설치해 주어야 한다.
https://sites.google.com/a/chromium.org/chromedriver/downloads
이 사이트에 들어가서 자신의 chrome과 맞는 버전을 다운받아야 한다.
+) chrome 버전은 chrome 브라우저 오른쪽 끝에 더보기 -> 도움말 -> Chrome 정보를 통해 확인할 수 있다.
설치를 완료했으면 자신의 PATH 디렉토리 하위에 chromedriver을 위치시킨다. 이렇게 하면 이후 다양한 프로젝트에서 드라이버를 호출할 때 유용하기에 권장하는 방법이다.
나의 경우는 python, pip 등의 명령어가 모여있는 /usr/local/bin 디렉토리로 chromedriver를 이동시켰다.
sudo mv {…/chromdriver} /usr/local/bin # 설치한 chromedriver 경로 -> /usr/local/bin
여기까지 진행했으면 기본 세팅은 끝났다.
코드
<전체 코드>
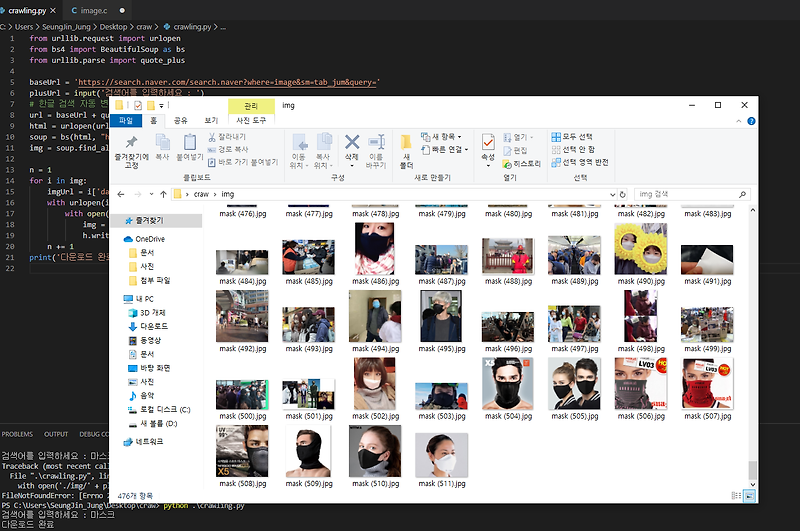
from selenium import webdriver from urllib.parse import quote_plus from urllib.request import urlopen import os def save_images(images, save_path): for index, image in enumerate(images[:10]): # images[:크롤링하고 싶은 사진 개수] src = image.get_attribute(‘src’) t = urlopen(src).read() file = open(os.path.join(save_path, str(index + 1) + “.jpg”), “wb”) file.write(t) print(“img save ” + save_path + str(index + 1) + “.jpg”) def create_folder_if_not_exists(directory): try: if not os.path.exists(directory): os.makedirs(directory) except OSError: print(‘Error: Creating directory. ‘ + directory) def make_url(search_term): # 네이버 이미지 검색 base_url = ‘https://search.naver.com/search.naver?where=image§ion=image&query=’ # CCL 상업적 이용 가능 옵션 end_url = ‘&res_fr=0&res_to=0&sm=tab_opt&color=&ccl=2’ \ ‘&nso=so%3Ar%2Ca%3Aall%2Cp%3Aall&recent=0&datetype=0&startdate=0&enddate=0&gif=0&optStr=&nso_open=1’ return base_url + quote_plus(search_term) + end_url def crawl_images(search_term): # URL 생성 url = make_url(search_term) # chrome 브라우저 열기 browser = webdriver.Chrome(‘chromedriver’) browser.implicitly_wait(3) # 브라우저를 오픈할 때 시간간격을 준다. browser.get(url) # 이미지 긁어오기 images = browser.find_elements_by_class_name(“_image”) # 저장 경로 설정 save_path = “/Users/danuri/Desktop/images/” + search_term + “/” create_folder_if_not_exists(save_path) # 이미지 저장 save_images(images, save_path) # 마무리 print(search_term + ” 저장 성공”) browser.close() if __name__ == ‘__main__’: crawl_images(input(‘원하는 검색어: ‘))
함수로 분리해서 그렇지 복잡한 코드는 아니다. 아래서부터 위로 올라가면서 알아보자.
if __name__ == ‘__main__’: crawl_images(input(‘원하는 검색어: ‘))
프로그램 시작 시 원하는 검색어를 입력해서 이미지 크롤링을 시작한다.
<이미지 크롤링>
def crawl_images(search_term): # URL 생성 url = make_url(search_term) # chrome 브라우저 열기 browser = webdriver.Chrome(‘chromedriver’) browser.implicitly_wait(3) # 브라우저를 오픈할 때 시간간격을 준다. browser.get(url) # 이미지 긁어오기 images = browser.find_elements_by_class_name(“_image”) # 저장 경로 설정 save_path = “/Users/danuri/Desktop/images/” + search_term + “/” create_folder_if_not_exists(save_path) # 이미지 저장 save_images(images, save_path) # 마무리 print(search_term + ” 저장 성공”) browser.close()
이미지를 크롤링하는 중심 함수다. 위에서부터 알아보자.
1. URL 생성
url = make_url(search_term) def make_url(search_term): # 네이버 이미지 검색 base_url = ‘https://search.naver.com/search.naver?where=image§ion=image&query=’ # CCL 상업적 이용 가능 옵션 end_url = ‘&res_fr=0&res_to=0&sm=tab_opt&color=&ccl=2’ \ ‘&nso=so%3Ar%2Ca%3Aall%2Cp%3Aall&recent=0&datetype=0&startdate=0&enddate=0&gif=0&optStr=&nso_open=1’ return base_url + quote_plus(search_term) + end_url
네이버 이미지 검색 URL + 검색어(search_term) + CCL 상업적 이용 가능 옵션을 이어서 크롤링하고자 하는 URL로서 사용한다.
2. chrome 브라우저 열기
browser = webdriver.Chrome(‘chromedriver’) browser.implicitly_wait(3) # 브라우저를 오픈할 때 시간간격을 준다. browser.get(url)
– webdriver.Chrome(‘chromedriver’): 아까 설치한 chromedriver를 사용해 크롬 페이지를 연다.
– implicitly_wait(3): 브라우저를 오픈할 때 약간의 시간간격을 줘야 이미지가 크롤링된다. 실제로 해당 부분 코드를 지우면 브라우저가 열리자마자 닫힌다.
– get(url): chrome에서 해당 url로 접속한다.
3. 이미지 긁어오기
images = browser.find_elements_by_class_name(“_image”)
네이버 이미지 검색 페이지 HTML을 분석해보면 각 이미지들이 ‘_image’ 클래스를 갖고 있다. 이를 전부 긁어온다.
4. 저장 경로 설정
save_path = “/Users/danuri/Desktop/images/” + search_term + “/” create_folder_if_not_exists(save_path) def create_folder_if_not_exists(directory): try: if not os.path.exists(directory): os.makedirs(directory) except OSError: print(‘Error: Creating directory. ‘ + directory)
각자 원하는 저장 경로를 설정한다. 나는 ‘바탕화면/images/김치찌개’ 로 검색어마다 ‘images/[검색어]’ 디렉토리에 저장되도록 설정했다.
create_folder_if_not_exists는 해당 저장경로가 존재하지 않으면 생성해주는 함수다.
5. 이미지 저장
save_images(images, save_path) def save_images(images, save_path): for index, image in enumerate(images[:10]): # images[:크롤링하고 싶은 사진 개수] src = image.get_attribute(‘src’) t = urlopen(src).read() file = open(os.path.join(save_path, str(index + 1) + “.jpg”), “wb”) file.write(t) print(“img save ” + save_path + str(index + 1) + “.jpg”)
설정한 저장 경로(save_path)에 긁어온 이미지들(images)을 저장한다.
나는 검색어당 10장이면 충분해서 10장만 저장하도록 했다. (1.jpg ~ 10.jpg)
6. 마무리
print(search_term + ” 저장 성공”) browser.close()
마지막으로 chrome 브라우저를 닫아준다.
<실행 결과>
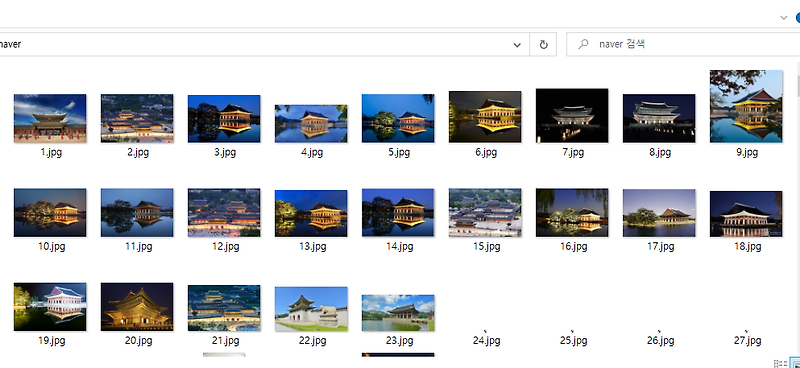
원하는 검색어: 김치찌개 img save /Users/danuri/Desktop/images/김치찌개/1.jpg img save /Users/danuri/Desktop/images/김치찌개/2.jpg img save /Users/danuri/Desktop/images/김치찌개/3.jpg img save /Users/danuri/Desktop/images/김치찌개/4.jpg img save /Users/danuri/Desktop/images/김치찌개/5.jpg img save /Users/danuri/Desktop/images/김치찌개/6.jpg img save /Users/danuri/Desktop/images/김치찌개/7.jpg img save /Users/danuri/Desktop/images/김치찌개/8.jpg img save /Users/danuri/Desktop/images/김치찌개/9.jpg img save /Users/danuri/Desktop/images/김치찌개/10.jpg 김치찌개 저장 성공
크롤링 성공!
Naver 이미지 크롤러
이미지 크롤러 – Naver
Naver Open API를 이용한 이미지 url 가져오기
공식적인 방법으로 어플리케이션을 등록을 통해 API를 사용할 수 있다.
import urllib.request import json client_id = “XXXXXX” client_secret = “XXXXXX” encText = urllib.parse.quote(“아이유”) url = “https://openapi.naver.com/v1/search/image?query=” + encText + “&sort=sim&display=100” request = urllib.request.Request(url) request.add_header(“X-Naver-Client-Id”, client_id) request.add_header(“X-Naver-Client-Secret”, client_secret) response = urllib.request.urlopen(request) rescode = response.getcode() if (rescode == 200): response_body = response.read() response_json = json.loads(response_body.decode(‘utf-8’)) else: print(“Error Code:” + rescode)
웹드라이버를 이용한 방법에 비해 옛날 이미지가 많이 포함되어 있다.
매우 빠른 검색 속도
하루 25,000 쿼리 제한
쿼리당 최대 1000개의 이미지 획득가능
Selenium을 이용한 웹페이지 파싱
Selenium 은 브라우저의 웹드라이버를 이용하여 웹사이트의 동작을 테스트한다. 따라서 현재 사용중인 브라우저 버전과 호환가능한 웹드라이버를 다운로드 받아야한다. 크롬 브라우저의 웹 드라이버는 link에서 다운로드할 수 있다.
Naver 검색창의 웹페이지 동작을 분석하고 아래의 웹드라이버의 동작을 구현하여 이미지 url을 가져올 수 있다.
1. 키워드 검색 2. 스크롤 3. img 태그에서 src 속성값 획득 4. url 중복 제거
[Naver] 스크롤네이버 이미지 검색에서 더 이상 스크롤 할수 없는 경우 로딩창의 style 속성에 display가 ‘none’으로 설정된다.